 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTX-2: Efficient Joint Audio-Visual Foundation Model
Jan 06, 2026Recent text-to-video diffusion models can generate compelling video sequences, yet they remain silent -- missing the semantic, emotional, and atmospheric cues that audio provides. We introduce LTX-2, an open-source foundational model capable of generating high-quality, temporally synchronized audiovisual content in a unified manner. LTX-2 consists of an asymmetric dual-stream transformer with a 14B-parameter video stream and a 5B-parameter audio stream, coupled through bidirectional audio-video cross-attention layers with temporal positional embeddings and cross-modality AdaLN for shared timestep conditioning. This architecture enables efficient training and inference of a unified audiovisual model while allocating more capacity for video generation than audio generation. We employ a multilingual text encoder for broader prompt understanding and introduce a modality-aware classifier-free guidance (modality-CFG) mechanism for improved audiovisual alignment and controllability. Beyond generating speech, LTX-2 produces rich, coherent audio tracks that follow the characters, environment, style, and emotion of each scene -- complete with natural background and foley elements. In our evaluations, the model achieves state-of-the-art audiovisual quality and prompt adherence among open-source systems, while delivering results comparable to proprietary models at a fraction of their computational cost and inference time. All model weights and code are publicly released.
Exploring Computational User Models for Agent Policy Summarization
May 30, 2019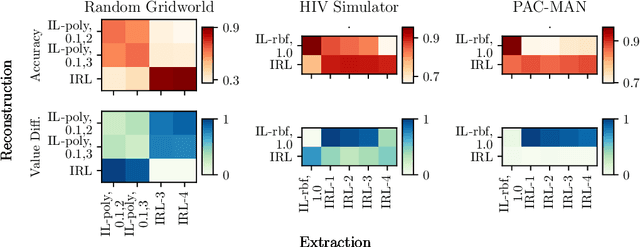


AI agents are being developed to support high stakes decision-making processes from driving cars to prescribing drugs, making it increasingly important for human users to understand their behavior. Policy summarization methods aim to convey strengths and weaknesses of such agents by demonstrating their behavior in a subset of informative states. Some policy summarization methods extract a summary that optimizes the ability to reconstruct the agent's policy under the assumption that users will deploy inverse reinforcement learning. In this paper, we explore the use of different models for extracting summaries. We introduce an imitation learning-based approach to policy summarization; we demonstrate through computational simulations that a mismatch between the model used to extract a summary and the model used to reconstruct the policy results in worse reconstruction quality; and we demonstrate through a human-subject study that people use different models to reconstruct policies in different contexts, and that matching the summary extraction model to these can improve performance. Together, our results suggest that it is important to carefully consider user models in policy summarization.